Kafka 是什么?为什么需要Kafka?
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
流式数据平台
- 类似消息系统,提供事件流的发布和订阅,数据注入功能
- 存储事件流数据的节点具有故障容错的特点,数据存储功能
- 能够对实时的事件流进行流式的处理和分析,流处理功能

消息系统主要有两种消息模型:队列和发布订阅,Kafka使用consumer group 统一两种消息模型。使用队列,可以将处理的工作平均分配给消费者组成员;使用订阅发布,消息广播给多个消费者组。采用多个消费者组结合多个消费者,既可以线性扩展消息的处理能力,也允许消息被多个消费者组订阅。
为什么要有消息队列?
- 解耦
- 冗余
- 扩展性
- 灵活性和峰值处理能力
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
主要概念和术语
- topic 只是一个逻辑概念,代表了一类消息。生产和消费需要指定topic。
- partition topic物理上的分组,一个topic可以分为多个partion,每个partion是一个有序的队列。是kafka横向扩展和一切并行化的基础。
- offset 消息在partition中的编号,编号顺序不跨partition
- replica 副本,replica是针对partition进行数据冗余,以实现数据的的高可靠,还有整个服务的高可用。根据 kafka 副本机制的定义,同一个分区下的所有副本保存有相同的消息序列,这些副本分散保存在不同的 broker 上,从而能够对抗部分 broker 宕机带来的数据不可用。
- leader 和 follower replia分为两类:leader replia和follower replia。只有leader replia能读写,follower replica是不能提供服务给客户端的,也就是说不负责响应客户端发来的消息写入和消息消费请求。它只是被动地向leader replia获取数据,而一旦leader replica 所在的broker宕机,kafka会从剩余的replica中选举出新的leader继续提供服务。
- ISR(In-Sync Replica) 是replicas的一个子集,表示目前alive且与leader能够Catch-up的replicas集合。
- broker kafka集群中的一台或多台服务器统称broker
- producer 应用程序发布事件流到kafka的一个或多个topic
- consumer 应用程序订阅kafka的一个或多个topic,并处理事件流
- consumer group 消费者组,可以并行消费topic中的partition的消息
- connector 将kafka topic和已有数据源进行链接,数据可以互相导人和导出
- processor 从kafka topic消费输入流,经过处理后,产生输出流到输出主题
Kafka 高可靠,高可用
高可靠一般是指消息高可靠,主要是基于副本设计。高可用一般是指机器出现宕机等异常情况依旧能正常提供服务,在服务端的体现的话,主要是就是controller的设计,ISR的设计,以及副本的主从设计。
副本机制和容错处理

副本同步机制,kafka每个topic的partition有N(N>=1)个副本,其中N由replica factor这个配置项决定。kafka通过多个副本实现故障的自动转移。当kafka集群中一个节点挂掉后可以保证服务仍然正常。多个副本中有一个副本为leader,其余为follower。 leader负责处理针对该partition的所有读写请求,follower能自动的从leader复制数据。
-
当leader挂掉后,会通过选举机制从follower中产生一个新的leader。加入之前的leader已有的数据条数为5,被选举的follower只复制了其中3条,那么consumer从新的leader获取数据就会出现问题,这种情况下如何保证数据正确性?
-
若某个follower出现故障,导致复制数据出现异常,该如何保证系统可靠性?
kafka引入了HW(HighWaterMark)和ISR(In Sync Replicas)
HW相关的还有LEO,LEO是LogEndOffset的缩写,标识每个partition的log最后一条message的位置。HW是指consumer能够读到的此partition最新的位置。

ISR是指副本同步,副本对于kafka的吞吐率有一定的影响,但是极大的增强了可用性,默认情况下Kafka的replica数量为1,即每个partition都有一个唯一的leader,为了确保消息的可靠性,通常应用中将其值(由broker的参数offsets.topic.replication.factor指定)大小设置为大于1,比如3。所有的副本(replicas)统称为Assigned Replicas,即AR。ISR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度。任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中,AR=ISR+OSR。
基于HW和ISR的消息同步
一个partition中取ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broKer的读取请求,没有HW的限制。

- follower和leader数据一致,HW和LEO也一致,无需复制。
- leader接收到producer写入的数据,此时LEO移动,两个follower开始复制数据。
- follower1完全复制了消息,follower2只复制了一部分,HW移动一位。
- follower2完全复制消息,HW和LEO一致。
数据是由leader push过去还是有flower pull过来? kafka是由follower周期性或者尝试去pull(拉)过来,写是都往leader上写,但是读并不是任意flower上读都行,读也只在leader上读,flower只是数据的一个备份,保证leader被挂掉后顶上来,并不往外提供服务。
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。ISR是动态伸缩的,可能出现follower全部都挂了,ISR中只剩下leader,那么此时设置acks=all就等价于acks=1了。kafka提供了参数:min.insync.replicas。配置最少ISR中需要多少个副本,才能继续提供写服务。如果设置为2,一旦ISR中的个数小于2,那么就不再提供写服务,牺牲一定的可用性,来保障这种高可靠的场景需求。
server配置
rerplica.lag.time.max.ms=10000
rerplica.lag.max.messages=4000
如果leader发现flower超过10秒没有向它发起fech请求,那么leader考虑这个flower是不是程序出了点问题或者资源紧张调度不过来,它太慢了,不希望它拖慢后面的进度,就把它从ISR中移除。相差4000条就移除,flower慢的时候,保证高可用性,同时满足这两个条件后又加入ISR中,在可用性与一致性做了动态平衡。
kafka消息保证机制,request.required.acks
- 0:不等待broker返回确认消息,不需要leader给予回复,producer立即返回,发送就是成功
- 1:等待topic中某个partition,当leader接收到消息之后发送ack,丢会重发,丢的概率很小(默认)
- -1:等待topic中某个partition 所有副本都保存成功的状态反馈,丢失消息可能性比较低
ISR伸缩过程
https://my.oschina.net/keepal/blog/5050479
Kafka 高性能
- 提高IO
- 减少计算
Kafka 每次写入操作其实都只是把数据写入到操作系统的页缓存(page cache)中,然后由操作系统自行决定什么时候把页缓存中的数据写入磁盘上。
Kafka在磁盘上只做Sequence I/O,关于磁盘I/O的性能,引用一组Kafka官方给出的测试数据(Raid-5,7200rpm)。
Sequence I/O: 600MB/s
Random I/O: 100KB/s
- 操作系统页缓存是内存中分配的,所以消息写入的速度非常快
- kafka不必直接与底层的文件系统打交道。所以烦琐的I/O操作都交由操作系统来处理
- kafka写入操作采用追加写入(append)方式,避免了磁盘随机写操作,顺序磁盘I/O速度快。
- 使用Sendfile,零拷贝技术加强网络间的数据传输效率

传统的方法整个过程共经历两次Context Switch,四次System Call。
- OS 从硬盘把数据读到内核区的PageCache。
- 用户进程把数据从内核区Copy到用户区。
- 然后用户进程再把数据写入到Socket,数据流入内核区的Socket Buffer上。
- OS 再把数据从Buffer中Copy到网卡的Buffer上,这样完成一次发送。
Kafka 的文件存储机制
在kafka服务器,分区是以目录形式存在的,每个分区目录中,Kafka会按配置大小(默认一个文件是1G,可以手动去设置)或配置周期将分区拆分成多个段文件(LogSegment)。每一个数据文件都被称为一个段(segment file),但每个段消息数量不一定相等,这种特性能够使得老的segment可以被快速清除。默认保留7天的数据。每次满1G后,在写入到一个新的文件中。每个段组成:
- 磁盘文件:*.log,用于存储消息本身的数据内容
- 位移索引文件:*.index,存储消息在文件中的位置(包括消息的逻辑offset和物理存储offset)
- 时间索引文件:*.timeindex,存储消息创建时间和对应逻辑地址的映射关系
log文件就是数据文件,里面存放的就是消息,而index文件是索引文件,索引文件记录了元数据信息。partition全局的第一个segment从0(20个0)开始,后续的每一个segment文件名是上一个segment文件中最后一条消息的offset值。
Kafka如何保证这种有序性呢?
partition只有一个,这种情况下是可以全局有序的。多个partition,单partition间隔有序,不连续。
Kafka如何查找数据?
跳表、稀疏索引
- 从所有文件log文件的的文件名中找到对应的log文件,第368776条数据位于上图中的“00000000000000368769.log”这个文件中。查找具体的Log Segment,kafka将段信息缓存在跳跃表中,所以这个步骤将从跳跃表中获取段信息。
- 到index文件中去找第368776条数据所在的位置。根据offset在index文件中进行定位,二分查找匹配范围的偏移量position,此时得到的是一个近似起始文件偏移量。
- 从log文件的position位置处开始往后寻找,直到找到offset处的消息。

上图的左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?
这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。那么多少条消息会在index中保存一条记录呢?这个可以通过系统配置来进行设置。索引记录固定为8个字节大小,分别为4个字节的相对offset(消息在partition中全局offset减去该segment的起始offset),4个字节的消息具体存储文件的物理偏移量。
其中以索引文件中元数据3,497为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第368772个消息), 其中497表示该消息的物理偏移地址(位置)为497。

批量发送消息
Kafka 作为一个消息队列, IO 密集型应用。包括磁盘IO和网络IO。磁盘顺序IO的速度其实非常快。对于网络IO,Kafka 采用了批量发送消息的方式,通过将多条消息按照分区进行分组,然后每次发送一个消息集合,从而大大减少了网络传输的 overhead。消息压缩,目的是为了进一步减少网络传输带宽。而对于压缩算法来说,通常是:数据量越大,压缩效果才会越好。压缩的本质取决于多消息的重复性,对比压缩单条消息,同时对多条消息进行压缩,能大幅减少数据量,从而更大程度提高网络传输率。其实压缩消息不仅仅减少了网络 IO,它还大大降低了磁盘IO。因为批量消息在持久化到 Broker 中的磁盘时,仍然保持的是压缩状态,最终是在Consumer端做了解压缩操作。
高效序列化
Kafka 消息中的 Key 和 Value,都支持自定义类型,只需要提供相应的序列化和反序列化器即可。因此,用户可以根据实际情况选用快速且紧凑的序列化方式(比如 ProtoBuf、Avro)来减少实际的网络传输量以及磁盘存储量,进一步提高吞吐量。
Kafka 高并发
- Reactor网络设计模式,将网络事件与业务逻辑进一步解耦
- NIO,多路复用网络IO模型
- Copy On Write 加锁copy写,无锁并发读
- 内存池设计
Partition Partition是Kafka可以很好的横向扩展和提供高并发处理以及实现Replication的基础。
扩展性方面。首先,Kafka允许Partition在集群内的Broker之间任意移动,以此来均衡可能存在的数据倾斜问题。其次,Partition支持自定义的分区算法,例如可以将同一个Key的所有消息都路由到同一个Partition上去。 同时Leader也可以在In-Sync的Replica中迁移。由于针对某一个Partition的所有读写请求都是只由Leader来处理,所以Kafka会尽量把Leader均匀的分散到集群的各个节点上,以免造成网络流量过于集中。
并发方面。任意Partition在某一个时刻只能被一个Consumer Group内的一个Consumer消费(反过来一个Consumer则可以同时消费多个Partition),Kafka非常简洁的Offset机制最小化了Broker和Consumer之间的交互,这使Kafka并不会像同类其他消息队列一样,随着下游Consumer数目的增加而成比例的降低性能。此外,如果多个Consumer恰巧都是消费时间序上很相近的数据,可以达到很高的PageCache命中率,因而Kafka可以非常高效的支持高并发读操作。
Partition的数量并不是越多越好,Partition的数量越多,平均到每一个Broker上的数量也就越多。考虑到Broker宕机(Network Failure, Full GC)的情况下,需要由Controller(主控制器)来为所有宕机的Broker上的所有Partition重新选举Leader,假设每个Partition的选举消耗10ms,如果Broker上有500个Partition,那么在进行选举的5s的时间里,对上述Partition的读写操作都会触发LeaderNotAvailableException。
在Broker端,对Producer和Consumer都使用了Buffer机制。其中Buffer的大小是统一配置的,数量则与Partition个数相同。如果Partition个数过多,会导致Producer和Consumer的Buffer内存占用过大。
Reactor网络设计模式,NIO
Reactor 网络通信模型
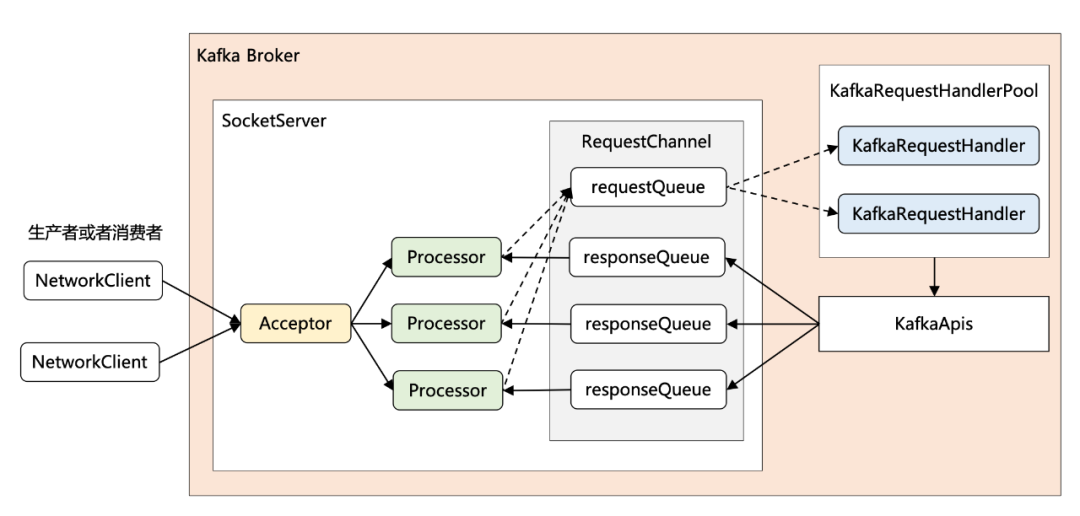
1 + N + M
- 1:表示 1 个 Acceptor 线程,负责监听新的连接,然后将新连接交给 Processor 线程处理
- N:表示 N 个 Processor 线程,每个 Processor 都有自己的 selector,负责从 socket 中读写数据。
- M:表示 M 个 KafkaRequestHandler 业务处理线程,它通过调用 KafkaApis 进行业务处理,然后生成 response,再交由给 Processor 线程。
内存池设计
Kafka 封装了一个内存结构,把每个分区的消息封装成批次,缓存到内存里。反复利用每一个批次,减少Java虚拟机的内存回收。
kafka控制器
主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。集群中任意一台 Broker 都能充当控制器的角色,但是,在运行过程中,只能有一个 Broker 成为控制器,行使其管理和协调的职责。
kafka控制器是如何被选出来的?
Broker 在启动时,会尝试去 ZooKeeper 中创建 /controller 节点。Kafka 当前选举控制器的规则是:第一个成功创建 /controller/id 节点的 Broker 会被指定为控制器。controller服务监听的目录:/broker/ids/ 用来感知 broker上下线 /broker/topics/ 创建主题,我们当时创建主题命令,提供的参数,ZK地址。/admin/reassign_partitions 分区重分配。
- 主题管理(创建、删除、增加分区),执行kafka-topics 脚本
- 分区重分配,执行kafka-reassign-partitions 脚本
- Preferred 领导者选举,Preferred 领导者选举主要是 Kafka 为了避免部分 Broker 负载过重而提供的一种换 Leader 的方案
- 集群成员管理,包括自动检测新增 Broker、Broker 主动关闭及被动宕机。这种自动检测是依赖于前面提到的 Watch 功能和 ZooKeeper 临时节点组合实现的。
- 数据服务,向其他 Broker 提供数据服务。控制器上保存了最全的集群元数据信息,其他所有 Broker 会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。
控制器故障转移,故障转移指的是,当运行中的控制器突然宕机或意外终止时,Kafka 能够快速地感知到,并立即启用备用控制器来代替之前失败的控制器。这个过程就被称为 Failover,该过程是自动完成的。

如何保证数据不丢失?
kafka消息保证机制
- At most once:消息可能会丢,但是绝对不会重复传递
- At least once:消息绝对不会丢,但是可能重复传递
- Exactly once:每条消息之传输一次仅被传输一次
broker如何保证数据的不丢失
- acks=all 所有副本都写入成功并确认。
- retries = 一个合理值。
- min.insync.replicas=2 消息至少要被写入到这么多副本才算成功。
- unclean.leader.election.enable=false 关闭unclean leader选举,即不允许非ISR中的副本被选举为leader,以避免数据丢失。
consumer如果保证数据得不丢失
- enable.auto.commit=false 关闭自动提交offset
zk的偏移量存储改成kafka存储
- zk不擅长高并发操作
- zk不适合高频读写操作
kafka支持高并发、高可用、高性能
延时任务
kafka的延迟调度机制。
第一类延时的任务:比如说producer的acks=-1,必须等待leader和follower都写完才能返回响应。有一个超时时间,默认是30秒(request.timeout.ms)。所以需要在写入一条数据到leader磁盘之后,就必须有一个延时任务,到期时间是30秒延时任务 放到DelayedOperationPurgatory(延时管理器)中。假如在30秒之前如果所有follower都写入副本到本地磁盘了,那么这个任务就会被自动触发苏醒,就可以返回响应结果给客户端了, 否则的话,这个延时任务自己指定了最多是30秒到期,如果到了超时时间都没等到,就直接超时返回异常。
第二类延时的任务:follower往leader拉取消息的时候,如果发现是空的,此时会创建一个延时拉取任务 延时时间到了之后(比如到了100ms),就给follower返回一个空的数据,然后follower再次发送请求读取消息, 但是如果延时的过程中(还没到100ms),leader写入了消息,这个任务就会自动苏醒,自动执行拉取任务。
时间轮机制
什么会有要设计时间轮?
Kafka内部有很多延时任务,没有基于JDK Timer来实现,那个插入和删除任务的时间复杂度是O(nlogn), 而是基于了自己写的时间轮来实现的,时间复杂度是O(1),依靠时间轮机制,延时任务插入和删除。
时间轮是什么?
其实时间轮说白其实就是一个数组。
tickMs:时间轮间隔 1ms wheelSize:时间轮大小 20 interval:timckMS * whellSize,一个时间轮的总的时间跨度。20ms currentTime:当时时间的指针。
因为时间轮是一个数组,所以要获取里面数据的时候,靠的是index,时间复杂度是O(1) 。数组某个位置上对应的任务,用的是双向链表存储的,往双向链表里面插入,删除任务,时间复杂度也是O(1)。
举例:插入一个8ms以后要执行的任务 19ms 3.多层级的时间轮
比如:要插入一个110毫秒以后运行的任务。
tickMs:时间轮间隔 20ms wheelSize:时间轮大小 20 interval:timckMS * whellSize,一个时间轮的总的时间跨度。20ms currentTime:当时时间的指针。
第一层时间轮:1ms * 20 第二层时间轮:20ms * 20 第三层时间轮:400ms * 20
Kafka常用操作命令
kafka-topics
Command Usage:
-----------------------------------------------------
create:
kafka-topics.sh --create --topic <topic name> --partitions <Integer: the number of partitions> --replication-factor <Integer: replication factor> --zookeeper <ZK_IP1:ZK_PORT,ZK_IP2:ZK_PORT,.../kafka>
kafka-topics.sh --create --topic <topic name> --partitions <Integer: the number of partitions> --replication-factor <Integer: replication factor> --bootstrap-server <IP1:PORT, IP2:PORT,...> --command-config <config file>
-----------------------------------------------------
delete:
kafka-topics.sh --delete --topic <topic name> --zookeeper <ZK_IP1:ZK_PORT,ZK_IP2:ZK_PORT,.../kafka>
kafka-topics.sh --delete --topic <topic name> --bootstrap-server <IP1:PORT, IP2:PORT,...> --command-config <config file>
-----------------------------------------------------
alter:
kafka-topics.sh --alter --topic <topic name> --zookeeper <ZK_IP1:ZK_PORT,ZK_IP2:ZK_PORT,.../kafka> --config <name=value>
-----------------------------------------------------
list:
kafka-topics.sh --list --zookeeper <ZK_IP1:ZK_PORT,ZK_IP2:ZK_PORT,.../kafka>
kafka-topics.sh --list --bootstrap-server <IP1:PORT, IP2:PORT,...> --command-config <config file>
-----------------------------------------------------
describe:
kafka-topics.sh --describe --zookeeper <ZK_IP1:ZK_PORT,ZK_IP2:ZK_PORT,.../kafka>
kafka-topics.sh --describe --bootstrap-server <IP1:PORT, IP2:PORT,...> --command-config <config file>
-----------------------------------------------------
topic 分区重分配,分区首选副本选择
删除topic
zkCli.sh
ls /brokers/topics
rmr /brokers/topics/[topic 名称]
kafka-console-producer
Command Usage:
-----------------------------------------------------
kafka-console-producer.sh --broker-list <IP1:PORT, IP2:PORT,...> --topic <topic name> --producer.config <config file>
-----------------------------------------------------
kafka-console-consumer
Command Usage:
-----------------------------------------------------
kafka-console-consumer.sh --topic <topic name> --bootstrap-server <IP1:PORT, IP2:PORT,...> --consumer.config <config file>
-----------------------------------------------------
kafka-consumer-groups
--state Describe the group state. This option,may be used with '--describe' and '--bootstrap-server' options only.Example: --bootstrap-server localhost:9092 --describe --group group1 --state
Command Usage:
-----------------------------------------------------
list:
kafka-consumer-groups.sh --list --bootstrap-server <IP1:PORT, IP2:PORT,...> --command-config <config file>
-----------------------------------------------------
describe:
kafka-consumer-groups.sh --describe --bootstrap-server <IP1:PORT, IP2:PORT,...> --group <group name> --command-config <config file>
-----------------------------------------------------
kafka-run-class
topic 最早之前的 offset
kafka-run-class kafka.tools.GetOffsetShell --broker-list <IP1:PORT, IP2:PORT,...> -time -2 --topic <topic name>
topic 最近的 offset
kafka-run-class kafka.tools.GetOffsetShell --broker-list <IP1:PORT, IP2:PORT,...> -time -1 --topic <topic name>