kudu是什么
https://kudu.apache.org/docs/
kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器。支持水平扩展,高可用。
- OLAP 工作的快速处理
- 与 MapReduce,Spark 和其他 Hadoop 生态系统组件集成
- 与 Apache Impala(incubating)紧密集成,使其与 Apache Parquet 一起使用 HDFS 成为一个很好的可变的替代方案
- 强大而灵活的一致性模型,允许您根据每个 per-request(请求选择)一致性要求,包括 strict-serializable(严格可序列化)一致性的选项
- 针对同时运行顺序和随机工作负载的情况性能很好。
- High availability(高可用性)Tablet server *和 *Master 使用 Raft Consensus Algorithm 来保证节点的高可用,确保只要有一半以上的副本可用
- 结构化数据模型
kudu常见的几个应用场景
- 实时更新的应用,刚刚到达的数据就马上要被终端用户使用访问到。
- 时间序列相关的应用
- 根据海量历史数据查询
- 必须非常快地返回关于单个实体的细粒度查询
- 实时预测模型的应用,支持根据所有历史数据周期地更新模型
列式存储
Columnar Data Store(列式数据存储)
Kudu 是一个 columnar data store(列式数据存储)。列式数据存储在强类型列中。由于几个原因,通过适当的设计,Kudu 对 analytical(分析)或 warehousing(数据仓库)工作会非常出色。
Read Efficiency(高效读取)
对于分析查询,允许读取单个列或该列的一部分同时忽略其他列,这意味着您可以在磁盘上读取更少块来完成查询。与基于行的存储相比,即使只返回几列的值,仍需要读取整行数据。
Data Compression(数据压缩)
由于给定的列只包含一种类型的数据,基于模式的压缩比压缩混合数据类型(在基于行的解决方案中使用)时更有效几个数量级。结合从列读取数据的效率,压缩允许您在从磁盘读取更少的块时完成查询。
kudu和其他存储工具的对比
kudu的集群架构基本和HBase类似,采用主从结构,Master节点管理元数据,Tablet节点负责分片管理数据。和HBase不同的是,Kudu没有借助于HDFS存储实际数据,而是自己直接在本地磁盘上管理分片数据,包括数据的Replication机制,kudu的Tablet server直接管理Master分片和Slave分片,自己通过raft协议解决一致性问题等,多个Slave可以同时提供数据读取服务,相对于HBase依托HDFS进行Region数据的管理方式,自主性会强一些,不过比如Tablet节点崩溃,数据的迁移拷贝工作等,也需要Kudu自己完成。
kudu 环境搭建
安装kudu
https://kudu.apache.org/docs/quickstart.html
kudu 本地搭建kudu环境,启动docker kudu服务
git clone https://github.com/apache/kudu
cd kudu
export KUDU_QUICKSTART_IP=$(ifconfig | grep "inet " | grep -Fv 127.0.0.1 | awk '{print $2}' | tail -1)
docker-compose -f docker/quickstart.yml up -d
docker exec -it $(docker ps -aqf "name=kudu-master-1") /bin/bash
检查kudu服务的健康情况
kudu cluster ksck kudu-master-1:7051,kudu-master-2:7151,kudu-master-3:7251
kudu-impala docker启动kudu-impala服务,使用impala操作kudu
docker run -d --name kudu-impala --network="docker_default" \
-p 21000:21000 -p 21050:21050 -p 25000:25000 -p 25010:25010 -p 25020:25020 \
--memory=4096m apache/kudu:impala-latest impala
进入impala-shell
docker exec -it kudu-impala impala-shell
kudu操作
impala 操作
Kudu-Impala 集成特性
- CREATE/ALTER/DROP TABLE
- UPDATE / DELETE,Impala 支持 UPDATE和 DELETE SQL命令逐行或批处理修改kudu表中的已有的数据。
- Flexible Partitioning(灵活分区)
- Parallel Scan(并行扫描),Impala 使用的 Kudu 客户端可以跨多个 tablets 扫描
- High-efficiency queries(高效查询)
create database db_flink_26;
use db_flink_26;
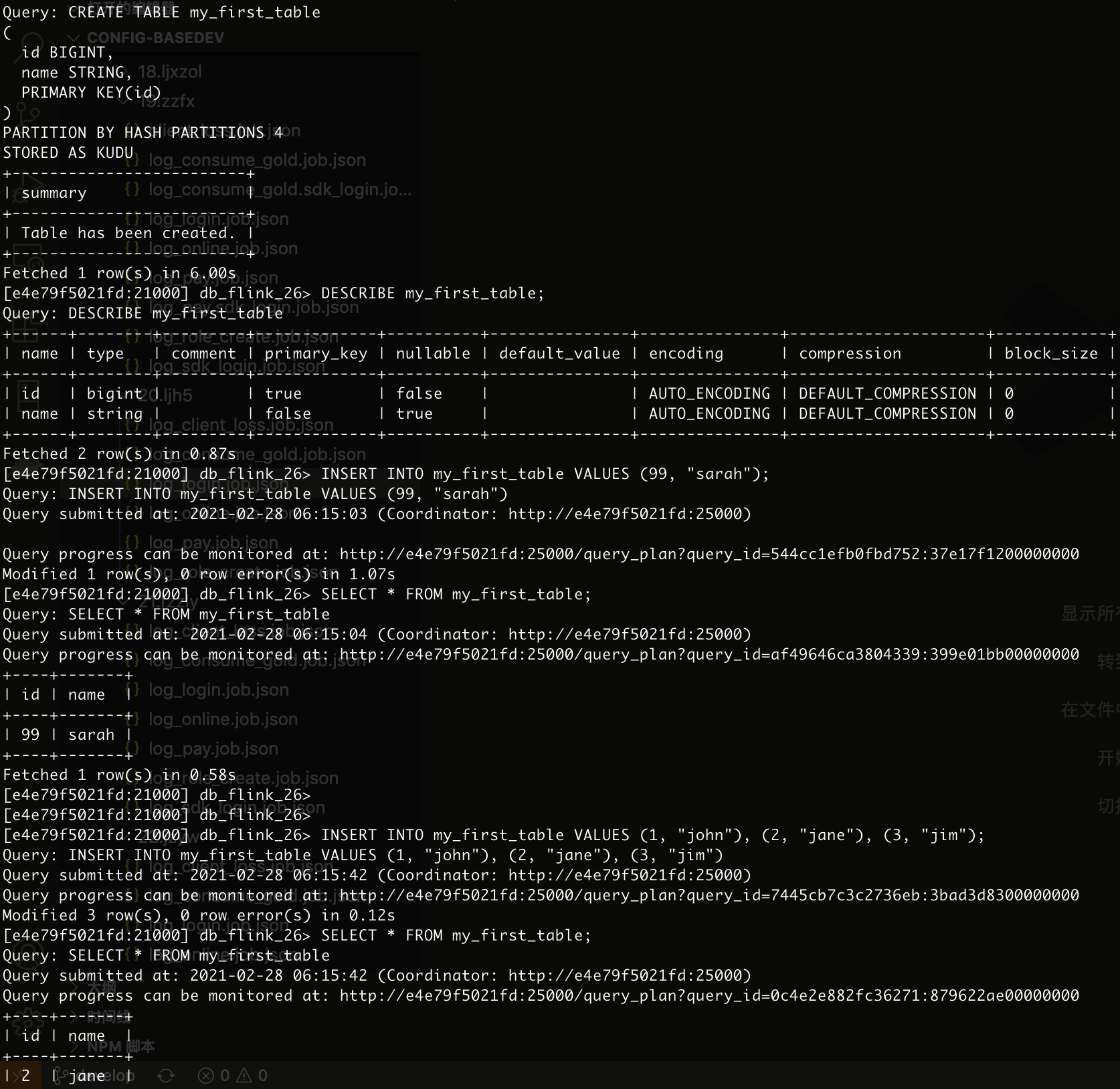
CREATE TABLE my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 4
STORED AS KUDU;
DESCRIBE my_first_table;
INSERT INTO my_first_table VALUES (99, "sarah");
SELECT * FROM my_first_table;
INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim");
SELECT * FROM my_first_table;
web访问
http://localhost:8050/ http://localhost:8051/
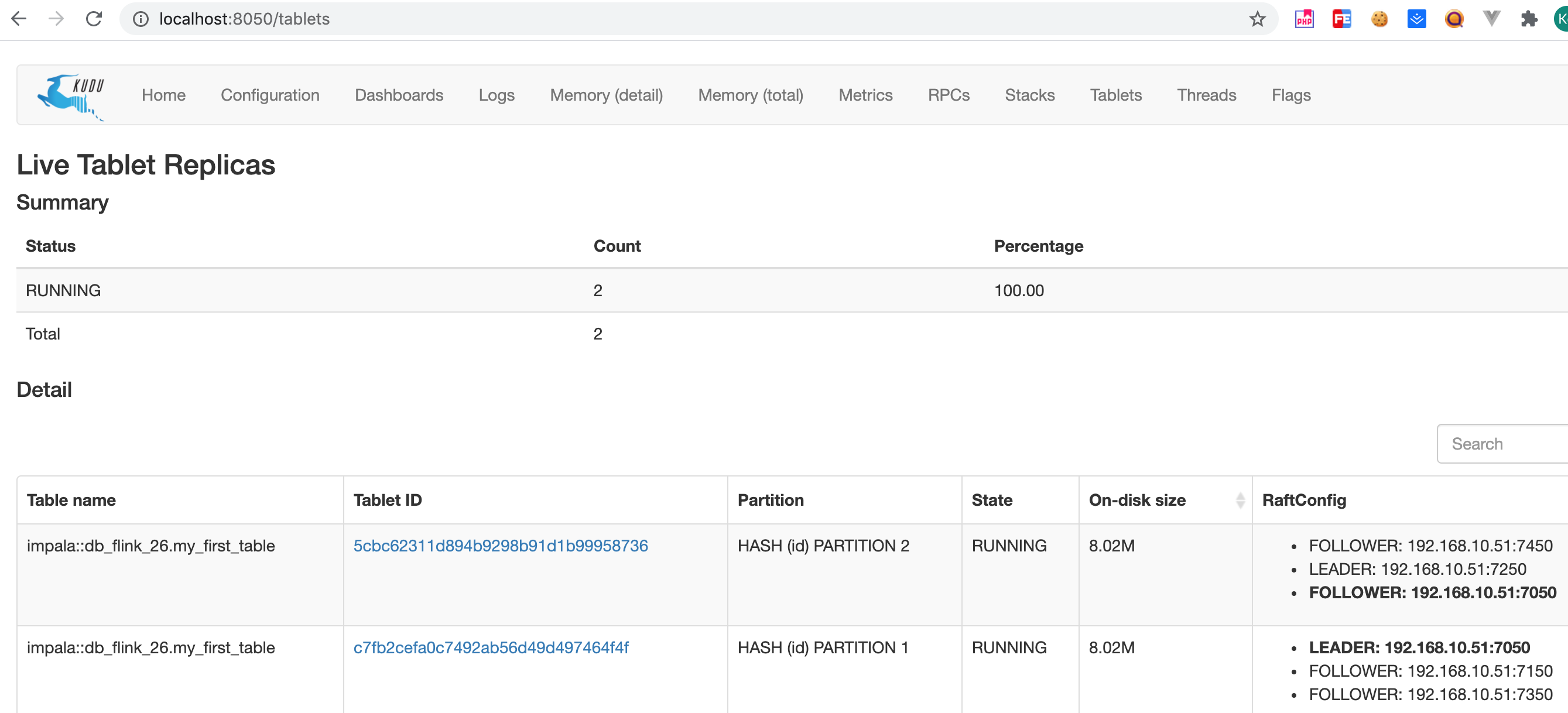
注意:
- kudu里面的表名格式是impala::库名.表名。
- 查询已经存在表,通过api或者spark创的表,impala看不到,需要创映射
CREATE EXTERNAL TABLE my_mapping_table
STORED AS KUDU
TBLPROPERTIES (
'kudu.table_name' = 'exist_kudu_table'
修改表的properties
ALTER TABLE my_table RENAME TO my_new_table;--只是修改了impala映射
ALTER TABLE my_internal_table
SET TBLPROPERTIES('kudu.table_name' = 'new_name');--仅限内部表,修改kudu底层表名
ALTER TABLE my_external_table_
SET TBLPROPERTIES('kudu.table_name' = 'some_other_kudu_table');--修改外部表到别的kudu表
ALTER TABLE my_table
SET TBLPROPERTIES('kudu.master_addresses' = 'ip:7051,...');--修改master地址
ALTER TABLE my_table SET TBLPROPERTIES('EXTERNAL' = 'TRUE');--内部表修改为外部
kudu java的操作示例
kudu example kudu/examples/java
kudu 命令行操作
kudu操作表
kudu table list kudu-master-1:7051,kudu-master-2:7151,kudu-master-3:7251
kudu table delete kudu-master-1:7051,kudu-master-2:7151,kudu-master-3:7251 表名
kudu 分区
https://kudu.apache.org/docs/schema_design.html
Kudu 提供了两种类型的分区:range partitioning ( 范围分区 ) 和 hash partitioning ( 哈希分区 )。表也可能具有 多级分区 ,其结合范围和哈希分区,或多个散列分区实例。
Range Partitioning ( 范围分区 )
Kudu 允许在运行时从表中动态添加和删除范围分区,而不影响其他分区的可用性。删除分区将删除属于分区的 tablet 以及其中包含的数据。随后插入到丢弃的分区将失败。可以添加新分区,但不能与任何现有的分区分区重叠。 Kudu 允许在单个事务性更改表操作中删除并添加任意数量的范围分区。
动态添加和删除范围分区对于时间序列使用情况尤其有用。随着时间的推移,可以添加范围分区以覆盖即将到来的时间范围。例如,存储事件日志的表可以在每月开始之前添加一个月份的分区,以便保存即将到来的事件。必要时可以删除旧范围分区,以便有效地删除历史数据。
Hash Partitioning ( 哈希分区 )
哈希分区通过哈希值将行分配到许多 buckets ( 存储桶 )之一。哈希分区是一种有效的策略,当不需要对表进行有序访问时。哈希分区对于在 tablet 之间随机散布这些功能是有效的,这有助于减轻热点和 tablet 大小不均匀。
Multilevel Partitioning ( 多级分区 )
Kudu 允许一个表在单个表上组合多级分区。零个或多个哈希分区级别可以与可选的范围分区级别组合。
Flink kudu 入库
Flink Kudu Connector
官方推荐的Connect适合单个表的操作。
https://bahir.apache.org/docs/flink/current/flink-streaming-kudu/
CREATE TABLE TestTable (
first STRING,
second STRING,
third INT NOT NULL
) WITH (
'connector.type' = 'kudu',
'kudu.masters' = '...',
'kudu.table' = 'TestTable',
'kudu.hash-columns' = 'first',
'kudu.primary-key-columns' = 'first,second'
)
自定义kudu sink
t_online、t_log_role_base_data测试表
CREATE TABLE db_flink_26.t_log_online (
pid BIGINT,
agent_id INT,
server_id INT,
time INT,
weekday INT,
year INT,
month INT,
day INT,
hour INT,
min INT,
online INT,
platform INT,
via STRING,
client_version STRING,
server_version STRING,
mtime INT,
pf_online STRING,
PRIMARY KEY (pid,agent_id,server_id)
)
COMMENT 'online table'
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'kudu-master-1:7051,kudu-master-2:7151,kudu-master-3:7251',
'kudu.num_tablet_replicas' = '1'
);
CREATE TABLE db_flink_26.t_log_role_base_data (
pid BIGINT,
agent_id INT,
server_id INT,
role_id BIGINT,
role_name STRING,
account_name STRING,
sex TINYINT,
create_time INT,
category TINYINT,
faction_id TINYINT,
level INT,
last_login_time INT,
ip STRING,
last_login_ip STRING,
fight INT,
money INT,
bind_gold INT,
gold INT,
bind_copper INT,
copper INT,
platform INT,
via STRING,
upf INT,
cid STRING,
last_offline_time INT,
regrow INT,
device_id STRING,
client_version STRING,
server_version STRING,
pay_money FLOAT,
is_vip INT,
mtime INT,
idfa STRING,
imei STRING,
is_retran TINYINT,
mac STRING,
family_id BIGINT,
family_level INT,
PRIMARY KEY (pid,agent_id,server_id)
)
COMMENT 'role_base'
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'kudu-master-1:7051,kudu-master-2:7151,kudu-master-3:7251',
'kudu.num_tablet_replicas' = '1'
);
主键中不支持更改,只能删除后重新添加
- 未指定分区字段时,其分区字段默认是主键,若主键有两个列则分区字段为两个,指定分区字段时,需要分区列是主键的子集;否则会报错
Only key columns can be used in PARTITION BY - 不指定分区:表依然会创建,但是只有一个分区,会提示
Unpartitioned Kudu tables are inefficient for large data sizes.
JAVA API 提供了三种向 kudu 插入数据的刷新策略
- AUTO_FLUSH_SYNC
- AUTO_FLUSH_BACKGROUND
- MANUAL_FLUSH
https://blog.csdn.net/CZ_yjsy_data/article/details/88390696
Flink 入库 Kudu
-
自定义Kudu Sink继承RichSinkFunction,实现open、invoke、close方法
-
从传入McLog的POJO结构中获取tableName和Logs
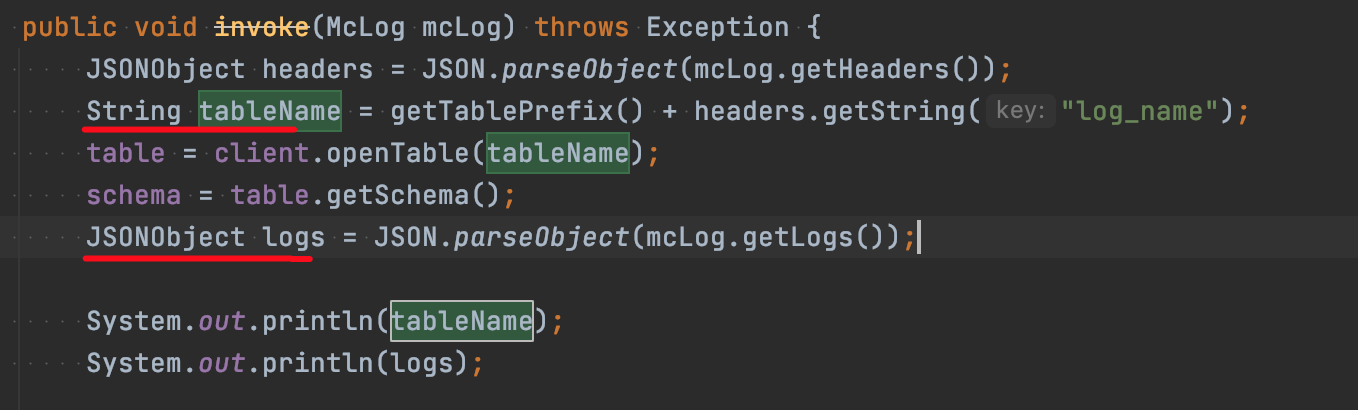
- DEMO使用AUTO_FLUSH_BACKGROUND的方式,打印出执行的数据
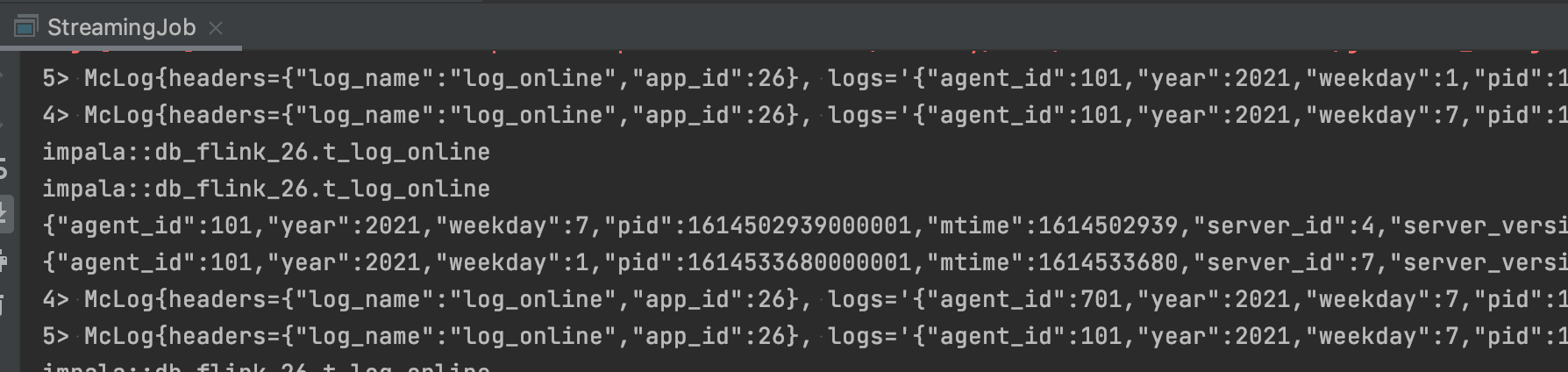
- 查看impala,可以看到数据已经入库
问题
kudu分区过多会导致CPU占用高,需要根据业务按需调整